PyVisA: Visualization and Analysis of Path Sampling results¶
In this example, we are going to familiarize with the use of PyVisA. Every example reported on the website can be used to generate the data to feed the analysis.
PyVisA is composed of two units: a compressor tool and a visualization tool (NB. the latter requires the additional installation of PyQt5). Both units can be executed directly via the pyvisa command or used as a Python library.
We illustrate here the usage of PyVisA components as a command line.
Please remember that, since clusters might not support GUI ad the relative packages (e.g. PyQt5), we opted to not include PyQt5 as a prerequisite for PyRETIS and PyVisA. This means that, to operate the GUI visualizer tool of PyVisA, PyQt5 has to be manually installed, e.g. via pip.
Compressor¶
The compressor tool can be executed with:
pyvisa -i <input_file> -cmp
where the <input_file> is the same file (.rst) used to execute the PyRETIS simulations.
PyVisA will read, for each folder, the energy and the order parameter files. It will check the consistency and integrity of each file and discard eventual corrupted data. The compressor tool will then generate a binary file, .hdf5 by default, where all the input files are condensed, compressed and organized such to simplify the following post-processing operations.
The compressor tool indicates eventual file inconsistencies, e.g. corrupted files or not corresponding cycles. This situation might happen when the simulation data have been produced by multiple machines and/or by multiple independent runs.
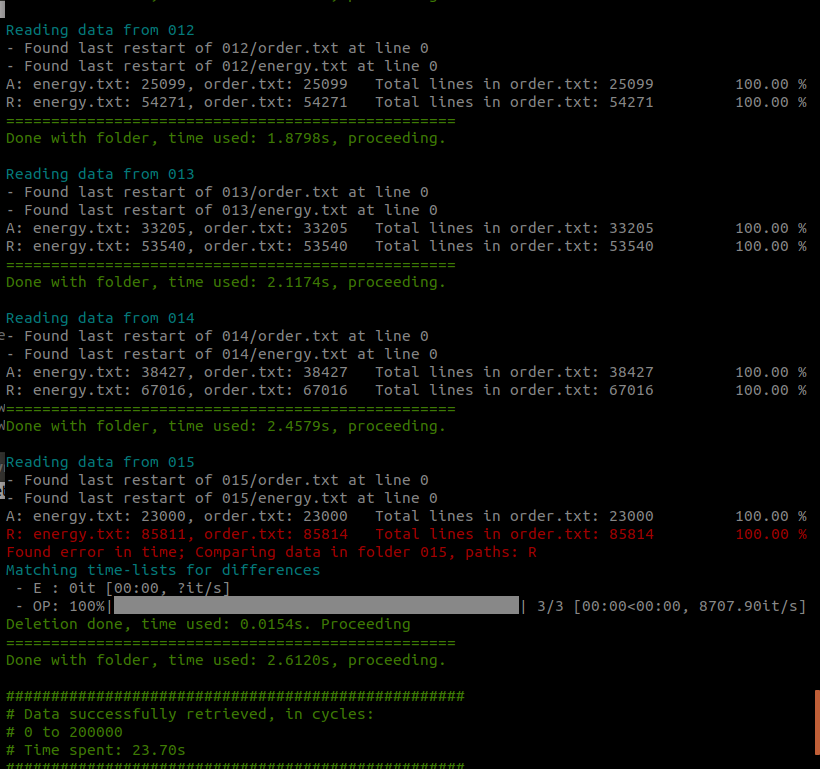
Fig. 47 A report on the reading and consistency check for each ensemble and for each file is provided by the compressor tool.¶
The source files are not touched by this operation. If the data consistency is very low, a manual check would be thus required to import the data.
Visualization¶
The visualization tool can be executed with:
pyvisa -i <input_file>
where the <input_file> can either be the .rst PyRETIS input file or the compressed file generated by the compressor tool (.hdf5).
PyVisA GUI has two main panels: data and plotting.
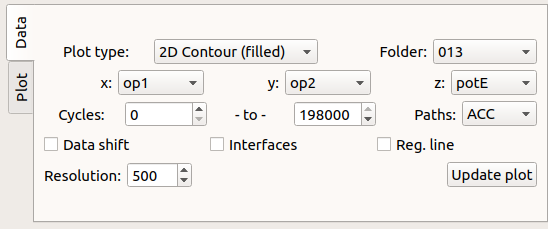
Fig. 48 Data panel: select the plotting type and data sub-set.¶
The plot types are defined by:
- Plot type: select the Matplot plot type and the number of dimensions to use. When plotting density maps, path weighting of accepted trajectories is an option.
Data sub-sets selection¶
Data selection and manipulation criteria are:
- x, y, z: list of order parameters, cycles and timesteps. Also, y, z allows the selection of the kinetic, potential, and total energy (kinetic+potential).
- Folder: choose an ensemble number or select all of them.
- Paths: accepted (ACC), rejected (REJ), or both (BOTH).
- Cycles: select the minimum and maximum cycle number, where a cycle is a Monte Carlo move, i.e. a trajectory for each ensemble.
- Data shift: shift the x - y data. This can be useful in the case of a cyclic order parameter such as an angle or dihedral.
- Interfaces: toggle interface lines (2D plot) or planes (3D plot) It requires that x is the main order parameter (OP1).
- Reg. line: plot a linear regression line and report its slope, intercept and r–squared values.
- Resolution: number of pixels or grid–points to use for density, surface plot types. For scatter plots, it controls the dot size.
Plotting¶
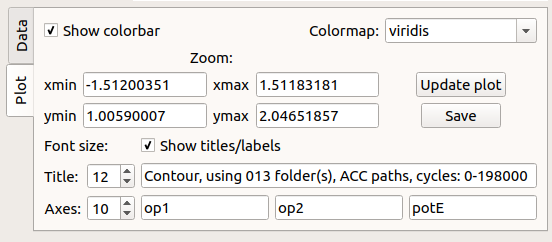
Fig. 49 Plotting panel: select the various plotting preferences.¶
From the GUI, without reloading the data, it is possible to manipulate the picture. The options are:
- Colormap: the colormaps to use for the plot.
- xmin/xmax: minimum and maximum x–values in the plot.
- ymin/ymax: minimum and maximum y–values in the plot.
- Save: save the figure in a .png file.
- Font size, Titles/Axes: the font size of plot titles and axis labels.
- Show titles/labels: display the plot titles and axis labels.
Data handling¶
Further options can be accessed from the drop-down panel labeled **File**.
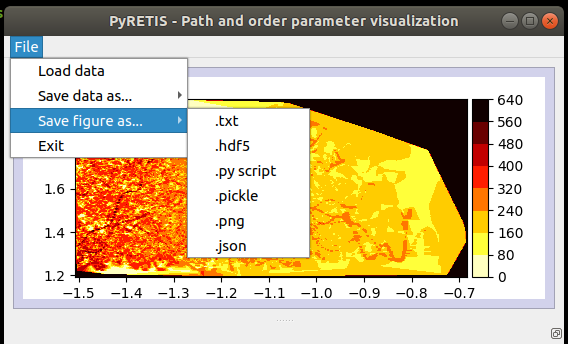
Fig. 50 A drop-down menu for file operations.¶
The drop-down menu contains a few options:
Data Loading: re-load the simulation compressed data.
Data Saving: save the simulation data, (e.g. use the compressor tool) in a .hdf5 format.
Figure save: save the current data selection/picture. Several options are here available. To further facilitate data handling, PyVisA can save the selected data in very different ways. The idea is to minimize user efforts in data manipulation. In all the following selections, the file name is automatically generated to contain all the information for (manually) reconstructing the plot.
The figure’s data can be saved in:
- Raw format: .txt file. Other visualization software can directly be used (e.g. xmgrace, gnuplot).
- JSON format: .json file. This allows users to directly access the numbers corresponding to a plot and/or load them via the JSON package.
The figure’s object can be saved in:
- .hdf5: a versatile compressed format that can be loaded also by other programming languages (e.g. R).
The figure itself can be saved as:
- figure.png: .png file.
- script.py: a Python program is generated to reproduce the selected plot from the compressed data simply by typing python <name_file.py>.
A large variety of plots can thus be generated via PyVisA. The respective data can be saved in different formats to further facilitate post-processing and analysis in different programming languages.